
앞선 포스팅에서 연구에서 사용할 변수 중 일부는 더미 변수로, 연속 변수는 기초 작업을 통해 회귀분석의 밑작업을 진행하였다. 이번 포스팅에서는 이러한 밑작업을 바탕으로 변인들간 상관관계를 분석해볼 것이다. 일반적으로 회귀분석을 진행하거나 회귀분석을 바탕으로 한 고급통계들, 예를 들면 구조방정식과 같은 분석을 사용할 때는 변수들간 상관관계를 제시해야 한다. 상관관계란 쉽게 말해 변수간의 연관을 의미하는 것이며, 그 정도를 상관계수로 나타낸다. 상관관계에 대한 이론적 개념이 좀 더 궁금하신 분이라면, 이전 포스팅을 참고하길 바란다.
2021.03.10 - [통계 공부/개념 및 이론] - 홍두승, 설동훈(2012). 사회조사분석 - Ch12. 회귀분석과 경로분석(1)
홍두승, 설동훈(2012). 사회조사분석 - Ch12. 회귀분석과 경로분석(1)
해당 포스팅은 홍두승과 설동훈이 집필한 「사회조사분석」의 내용을 정리한 것으로 모든 출처는 아래와 같다. 홍두승, 설동훈(2012). 「사회조사분석」. 서울: 다산출판사 Ch12. 회귀분석과 경
graduationplease.tistory.com
변수들간 상관관계를 분석하기 위해 사용할 수 있는 명령어에는 corr, pwcorr이 있다. 개인적으로는 pwcorr를 사용하는 편이기 때문에 해당 포스팅에서는 pwcorr로 설명을 진행하고자 한다.
pwcorr V1 n_child ses F_edu M_edu M_age V7 V8 V9 V10 V11 V12
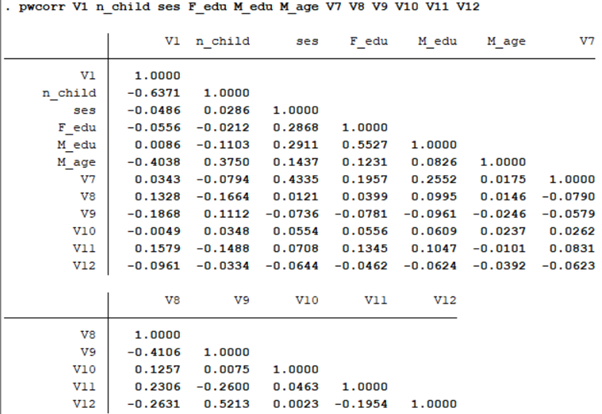
위의 syntax와 같이 입력하면 가장 기본적인 결과, 즉 변수들 간의 상관계수만을 도출해낼 수 있다. 하지만 여기서 연구자는 유의도를 함께 살펴봄으로써 해당 상관계수가 통계적으로 유의미한 값인지 판단을 내려야 한다. 이를 위한 옵션으로 sig를 사용해보도록 하자.
pwcorr V1 n_child ses F_edu M_edu M_age V7 V8 V9 V10 V11 V12, star(.05)
pwcorr V1 n_child ses F_edu M_edu M_age V7 V8 V9 V10 V11 V12, star(.01)
pwcorr V1 n_child ses F_edu M_edu M_age V7 V8 V9 V10 V11 V12, star(.001)
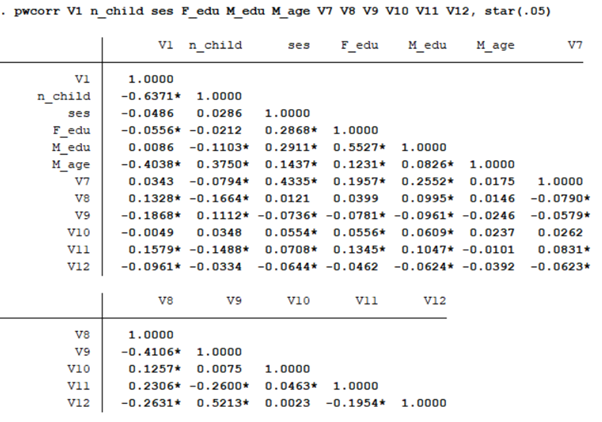


Syntax와 결과 사진을 비교해보면 알 수 있듯이, 상관계수 중 유의도가 star() 괄호 안에 쓰여진 값보다 작은 경우 별(*)표시가 붙는다. 예를 들어, 맨 마지막 사진을 보면 V1(후속출산계획: 더미변수)과 n_child(자녀수)는 p<.001 수준에서 음의 상관관계를 갖고 있는 것으로 나타났다. 반면 F_edu(아버지 학력)와 V11(부양육참여)는 p<.001 수준에서 양의 상관관계가 나타났다. 이러한 상관관계 분석표를 논문에 정리할 때, 엑셀을 이용하면 보다 손쉽게 표를 완성할 수 있다. 그 방법에 대해서는 이전 포스팅에서 정리해두었으므로, 아래 링크를 통해 확인하면 되겠다.
2020.04.18 - [통계 공부/Stata] - [Stata] 상관분석 관련 명령어: corr, pwcorr (+엑셀로 상관분석표 정리하기)
[Stata] 상관분석 관련 명령어: corr, pwcorr (+엑셀로 상관분석표 정리하기)
지금까지 Stata의 기본 명령어와 카이제곱/t-test/분산분석(ANOVA) 관련 명령어를 알아보았다. 이에 이어, 이번 포스팅에서는 상관분석과 관련한 stata 명령어를 알아볼 것이다. 논문의 연구결과 부분
graduationplease.tistory.com
'통계공부 > Stata' 카테고리의 다른 글
| [Stata] 기본 명령어(9): merge(+append, joinby) (0) | 2021.04.22 |
|---|---|
| 논문 따라 패널 데이터 분석하기: 서미정(2011)(11) (1) | 2021.04.12 |
| 논문 따라 패널 데이터 분석하기: 서미정(2011)(9) (0) | 2021.04.10 |
| 논문 따라 패널 데이터 분석하기: 서미정(2011)(8) (0) | 2021.04.01 |
| 논문 따라 패널 데이터 분석하기: 서미정(2011)(7) (0) | 2021.03.29 |