
이전 포스팅에 이어 한국아동패널의 1차년도 자료를 활용한 서미정(2011)의 논문을 따라 통계 분석을 진행해보았으며, 참고문헌은 아래와 같다.
서미정(2011). 부모의 심리사회적 특성이 후속 출산계획에 미치는 영향: 유자녀 가구를 중심으로. 육아정책연구, 5(1), 127-148.
이전 포스팅에서 최종 표본을 선정하고, 사용할 변수만을 추려놓았다. 이제 표본에 대한 기초 분석 자료를 얻기 위해, 인구사회학적 특성을 분석할 것이다. 서미정(2011)의 <표 1> 조사대상자의 인구학적 및 사회경제적 특성을 살펴보면 변인에는 자녀수, 이상자녀수, 가구소득, 부모 학력, 모 연령, 모 취업/학업이 있다. 하나씩 차근차근 살펴보자.
1. 자녀수
자녀수를 알기 위해 사용할 변수는 "아동" 출생순위(BCh08dmg002)이다. 여기서 의문이 들 수 있는 것이 해당 가정의 총 자녀수를 어떻게 아동 출생순위로 알 수 있는지인데, 이를 위해서는 한국아동패널에 대한 이해가 필요하다. 한국아동패널의 조사대상자는 1차년도 조사 시점인 2008년 4월부터 7월 중에 의료기관에서 출생한 신생아와 그 가정이다. 따라서 2008년에 출생한 아동은 당연히 조사시점 당시 해당 가정의 막내이기 때문에, 2008년생 아동의 출생순위를 통해 가정의 총 자녀수를 알 수 있는 것이다. 물론 윗 자녀 중 사망한 경우가 있다면 이러한 추측에 오류가 생기지만, 이러한 경우가 드물기 때문에 아동 출생순위 변수를 자녀수로 대체한 것이라 추측된다.
다시 분석으로 돌아와 "아동" 출생순위(BCh08dmg002)의 빈도분포표를 보도록 하자.
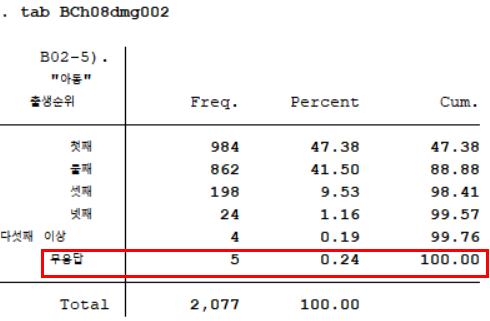
사진에서와 같이 '무응답'이 있기 때문에, 조사대상자의 인구학적 및 사회경제적 특성을 정리하기 위해서는 무응답을 결측치로 바꿔주어야 한다. 이를 위한 명령어는 아래와 같다.
recode BCh08dmg002 (1=1) (2=2) (3=3) (4=4) (5=5) (99999999=.), gen(n_child)
위의 명령에서 알 수 있듯이 첫째는 1, 둘째는 2, 셋째는 3, 넷째는 4, 다섯째 이상은 5, 무응답은 99999999라는 값으로 코딩이 되어 있다. 99999999로 코딩되어 있는 무응답을 결측치(.)로 처리하여 새로운 변수 'n_child'로 만들었다. 변수명은 분석하는 사람 마음대로 정하면 되는데, 기왕이면 변수에 대해 파악할 수 있도록 지어주는 것이 좋다. 그런 의미에서 필자는 number of children을 축약하여 n_child로 만들어보았다.

이렇게 리코딩한 n_child값의 빈도분포표를 정리하여 조사대상자의 인구학적 및 사회경제적 특성을 정리한다. 위의 사진에서 Freq(빈도)와 Percent 값을 표로 입력한다. 논문의 연구결과 작성에 관한 내용은 이전 포스팅에 정리한 것이 있으니, 이를 참고하길 바란다. ☞ 2020.03.14 - [논문 작성] - 논문 내용 구성(3): 연구결과
논문 내용 구성(3): 연구결과
이번 포스팅은 앞선 포스팅에 이어 논문 구성 중 연구결과에 관한 내용을 다룰 것이다. 예전 포스팅에서 언급했듯이, 해당 글은 사회과학계열 논문을 가정하고 작성하였으며 서론과 연구방법은
graduationplease.tistory.com
'통계공부 > Stata' 카테고리의 다른 글
| 논문 따라 패널 데이터 분석하기: 서미정(2011)(4) (0) | 2021.03.18 |
|---|---|
| 논문 따라 패널 데이터 분석하기: 서미정(2011)(3) (0) | 2021.03.17 |
| 논문 따라 패널 데이터 분석하기: 서미정(2011)(1) (0) | 2021.03.15 |
| [Stata] 다층모형 분석 관련 명령어(2): mixed (3) | 2021.02.17 |
| [Stata] 다층모형 분석 관련 명령어(1): mixed, estat icc (2) | 2021.02.16 |