
이번 포스팅에서는 지난 포스팅에 이어 분산분석(Analysis of Variance; ANOVA)과 관련한 stata 명령어를 알아보고자 한다. 앞선 포스팅에서 알아보았던 명령어는 oneway었는데, 이는 일원분산분석(one-way ANOVA)만 가능하기 때문에 이원분산분석(two-way ANOVA) 혹은 삼원분산분석(three-way ANOVA), 그리고 반복측정 분산분석(repeated-measures ANOVA)을 위한명령어로는 적합하지 않다. 그렇다면 이러한 분석들이 가능한 분산분석 관련 명령어는 무엇이 있을까?
*이번 포스팅에서도 Stata에 내장되어 있는 lifeexp와 auto2, bplong 데이터를 이용하여 예제 설명을 하고자 합니다.
1. anova
anova [종속변수] [요인(factor)]: one-way ANOVA를 실행하는 명령어
anova [종속변수] [요인1(factor2)] [요인1(factor2)]: two-way ANOVA를 실행하는 명령어
anova [종속변수] [요인1(factor2)] [요인1(factor2)] [요인1(factor2)##요인1(factor2)]:
위에서 상호작용 효과까지 추가
anova [종속변수] [반복 관련 변수(횟수, 시간 등)] [개인ID], repeated(반복 관련 변수):
반복측정 분산분석
Stata 명령어를 보면 알 수 있듯이, 상당히 명령어를 직관적으로 지었다. ANOVA 분석의 명령어는 바로 anova이다.
먼저, 일원분산분석부터 보도록 하자. 저번 포스팅에서 소개했던 oneway와 변수 나열 순서는 동일하다. 명령어 바로 뒤에는 종속변수, 즉 차이를 보고자 하는 변수를 입력하고 그 뒤에 요인(혹은 독립변수)을 넣어주면 된다. 앞선 포스팅에서와 같이, 지역에 따른 기대수명에 차이가 있는지 살펴보기 위해 다음과 같이 syntax를 입력한다.
anova lexp region
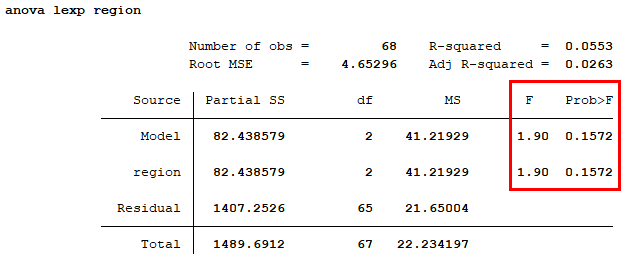
그러면 위와 같은 결과를 얻을 수 있다. F 값은 1.90, 유의확률은 .1572로 유의수준 .05보다 크기 때문에 영가설을 기각할 수 없다. 즉, 지역에 따라 기대수명에 차이가 있다고 말할 수 없다. 이는 앞선 포스팅에서 oneway로 돌렸을 때와 동일한 결과이다.
앞선 포스팅에서 소개한 oneway 명령어에서는 옵션을 활용하여 사후검증까지 진행할 수 있었다. 그렇다면 anova에서는 어떻게 사후검증을 할 것인가? 바로 pwcompare라는 명령어를 쓰면 된다. 자세한 내용은 아래 더보기를 클릭하시면 됩니다.
pwcompare는 바로 분석에서 쓸 수 있는 명령어가 아니라, anova 명령어 실행 후 사용할 수 있는 명령어이다. 앞서 기대수명이 지역에 따라 차이가 있는지 분산분석을 실행했기에(anova lexp region), 바로 pwcompare 명령어를 사용해보도록 하자.
pwcompare region, mcompare(tukey) effects
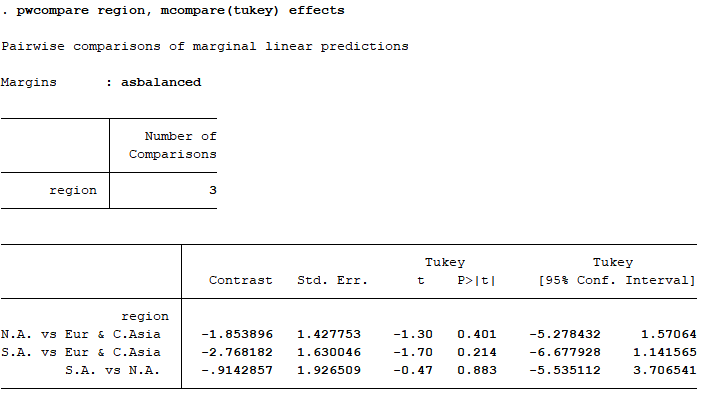
해당 명령어를 실행하면 다음과 같은 결과창을 얻을 수 있다. 여기서는 사후검증으로 tukey를 썼는데, scheffe나 bonferroni로도 변경 가능하다. 결과해석은 t값과 유의확률이 제시된 P>|t| 부분을 읽어주면 된다.
이번에는 이원분산분석 실행을 위해 stata에 내장되어 있는 auto2 데이터로 변경을 하자. 해당 데이터는 차에 관한 통계값들을 모아놓은 데이터로, 자동차의 가격(price), 자동차 브랜드와 모델(make), 마일리지(mpg), 무게(weight) 등의 변수 등이 저장되어 있다. 이 데이터를 활용하여 연구자는 차의 종류(국내domestic/해외foreign)와 수리기록(poor/fair/average/good/excellent)에 따라 차의 가격에 차이가 있는지 분석하고자 한다.

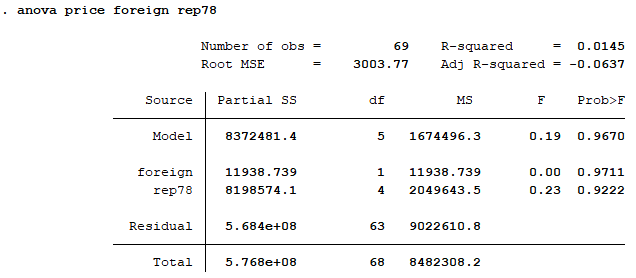
anova price foreign rep78
해당 syntax를 실행하면 다음과 같은 결과가 나온다. 결과를 보면, 수정된 R 스퀘어 값이 음수로 나와 해당 모형이 데이터에 제대로 맞지 않음을 알 수 있다. 하지만 이 포스팅은 어디까지나 stata 명령어를 위한 포스팅이므로 그냥 넘어가자.
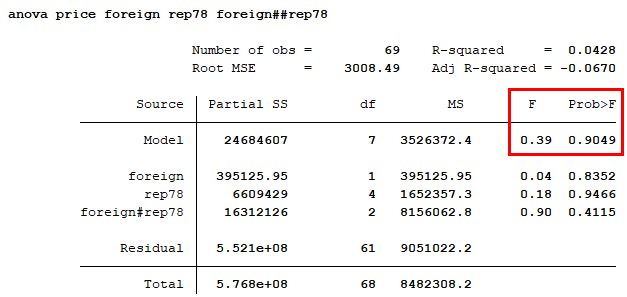
해당 분석에서 상호작용까지 추가하고 싶다면 foreign##rep78을 추가해주면 된다.
anova price foreign rep78 foreign##rep78
마지막으로, 반복측정 분산분석을 위한 예제를 보도록 하자. 이를 위해서는 bplong 데이터를 사용할 것이다. 해당 데이터는 연구대상자의 성별과 연령(범주형 변수), 혈압을 2차례 측정하여 저장한 데이터이다. 이 데이터를 활용하여, 환자들의 혈압이 전후로 차이가 있는지 알아보고자 다음과 같은 syntax를 입력하였다.
anova bp when patient, repeated(when)
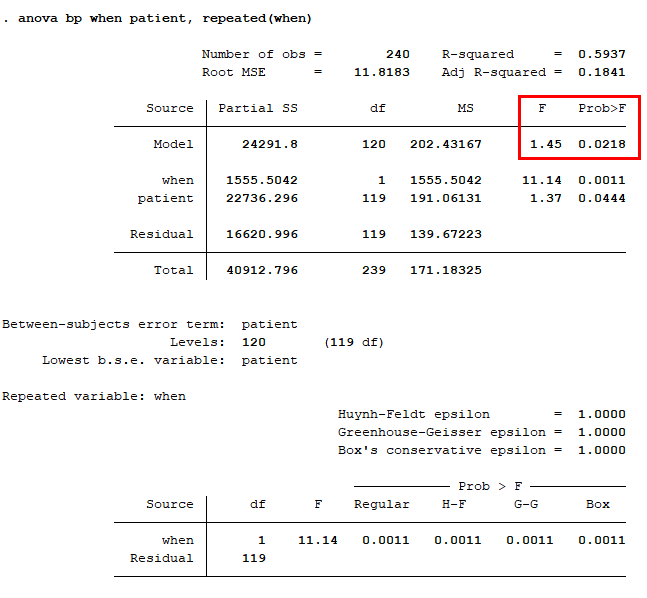
먼저 syntax부터 설명하면, anova 다음 종속변수인 혈압(bp; blood pressure)이 온다. 그 다음으로는 반복되는 걸 보여주는 변수, 대표적으로 횟수나 시간 등을 저장한 변수가 와야 한다. 해당 데이터에서는 when이라는 변수가 혈압을 before와 after 두 가지 경우로 나누어 측정했음을 알려준다. 마지막에 오는 변수는 개별 ID를 알려주는 patient(데이터 label을 보면 patient ID로 저장되어 있다.)를 입력해준다. 그리고 마지막으로 해당 분석이 반복측정 분산분석임을 알려주기 위해 ,repeated(when)을 추가하였다.
이제 결과창을 보면, F값이 1.45, p값이 .0218로 유의하게 나왔다. 즉, 환자의 혈압이 전후로 차이가 있게 나타났다.