
다층모형 분석은 무조건모형 분석 후 독립변수를 투입하는 조건모형 분석으로 2단계에 걸쳐 진행된다. 앞선 포스팅에서는 다층모형 분석 중 무조건모형 분석까지 설명하였으며, 이번 포스팅에서는 조건모형 분석을 이야기하고자 한다. 이전 포스팅의 예제를 그대로 가져와 설명할 예정이기에 앞선 포스팅을 읽고 넘어오는 것을 추천한다.
2021/02/16 - [통계 공부/Stata] - [Stata] 다층모형 분석 관련 명령어(1): mixed, estat icc
mixed 종속변수 || 2수준 변수: , var
mixed 종속변수 독립변수 || 2수준 변수: , var
mixed 종속변수 독립변수 || 2수준 변수: 독립변수, var cov(un)
다층모형 분석에 관한 기본 syntax는 위와 같으며, 이제 조건모형 분석을 진행하기 위해 종속변수에 영향을 미칠 것이라 예상되는 age와 grade, ttl_exp를 투입하고자 한다.
mixed wage age grade ttl_exp || race:, var
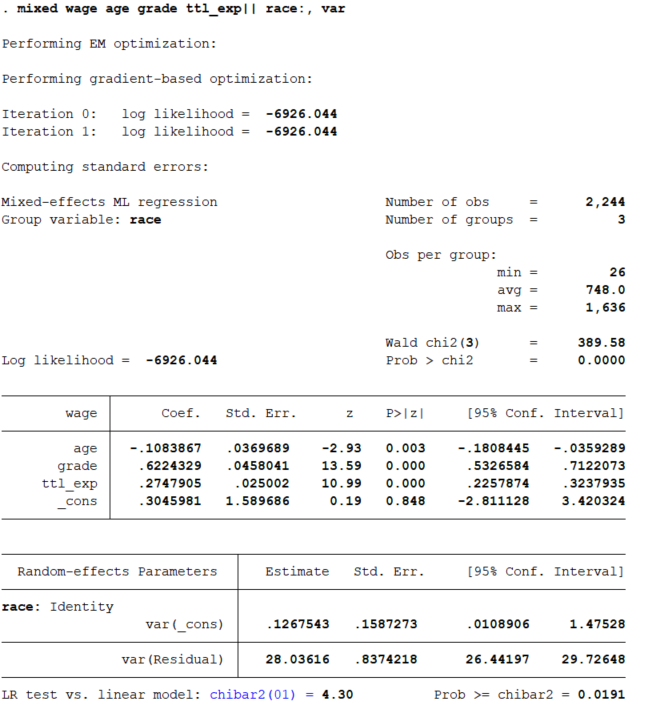
나아가 1수준의 효과가 2수준에 따라 다르다고 가정되는 변수가 있을 수 있다. 예를 들어, 학력(grade)의 효과가 인종(race)에 따라 다르다고 가정된다면 아래와 같이 syntax를 입력해야 한다.
mixed wage age grade ttl_exp || race: grade, var cov(un)
syntax를 자세히 살펴보면 아까와 달리 race: 뒤에 grade라는 독립변수를 추가로 입력하였으며, cov(un)이 붙어있는 것을 알 수 있다. 즉, grade라는 독립변수는 그 영향력이 인종에 따라 다르다고 가정되는 변수임을 의미하며 공분산을 추정하기 위해 cov(un)라는 옵션이 추가되었다.

또한 다층모형 분석에서 층위간 상호작용을 살펴볼 수 있는데, 이를 위해서는 다음과 같은 명령어를 쓰면 된다.
mixed wage 1수준의 독립변수(v1)#2수준의 독립변수2(v2) || race: , var
nlsw88 데이터에서는 마땅한 변수가 없어 예시를 들지 못했지만, 1수준과 2수준의 변수 중 상호작용 효과가 예측된다면 #이라는 기능을 사용하면 된다. 이는 앞선 회귀분석 포스팅에서 상호작용항을 넣기 위해 #을 투입했던 것과 같은 맥락이라 보면 된다.
다층모형 분석을 위한 Mplus와 Stata 명령어를 정리해보았다. 다만 유의할 점은 stata syntax를 설명하는 과정에서 분석결과에 대한 설명은 언급하지 않았다는 것이다. 예를 들어, 무조건 모형에서 종속변수의 총분산에 대한 그룹간 분산이 유의한지 확인하여야 하는데 이에 대해서는 본 포스팅에서 다루지 않았다. 또한 icc 값에 대한 추가 설명도 없다. 왜냐하면 앞선 stata 글들과 마찬가지로 해당 stata 포스팅에서는 syntax를 중심으로 설명을 하고 있을 뿐, 분석결과까지 세세히 다루기에는 분량의 한계가 있기 때문이다. 따라서 stata syntax를 입력하여 분석결과를 얻었다면, 이에 대한 해석 방법도 꼼꼼히 확인하여 데이터 분석을 진행하기를 바란다.
'통계공부 > Stata' 카테고리의 다른 글
| 논문 따라 패널 데이터 분석하기: 서미정(2011)(2) (0) | 2021.03.16 |
|---|---|
| 논문 따라 패널 데이터 분석하기: 서미정(2011)(1) (0) | 2021.03.15 |
| [Stata] 다층모형 분석 관련 명령어(1): mixed, estat icc (2) | 2021.02.16 |
| [Stata] 로지스틱 회귀분석 관련 명령어: logit, mlogit (3) | 2020.10.08 |
| [Stata] 회귀분석 관련 명령어(2): predict, rvfplot, estat, kdensity, swilk (0) | 2020.10.02 |