
다층모형 분석에 관한 Mplus syntax를 설명하는 포스팅에서 다층모형을 분석하기 위해 Mplus 외에도 HLM, Stata 등의 통계 프로그램을 사용할 수 있음을 언급하였다. 이에 이번 포스팅에서는 Stata를 이용해 다층모형 분석을 진행하는 방법을 알아보고자 한다. 다층모형 분석에 관한 이론적 설명과 Mplus syntax는 아래 포스팅들을 참고하면 된다.
☞이전 포스팅 참고
2021/02/12 - [통계 공부/Mplus] - [Mplus] 다층모형(Multilevel Modeling) syntax 설명(1)
2021/02/13 - [통계 공부/Mplus] - [Mplus] 다층모형(Multilevel Modeling) syntax 설명(2)
2021/02/14 - [통계 공부/Mplus] - [Mplus] 다층모형(Multilevel Modeling) syntax 설명(3)
다층모형 분석에 대한 기본 syntax는 다음과 같다.
mixed 종속변수 || 2수준 변수: , var
mixed 종속변수 독립변수 || 2수준 변수: , var
mixed 종속변수 독립변수 || 2수준 변수: 독립변수, var cov(un)
다층모형 분석에 관한 stata 설명을 위해, stata에 기본으로 탑재되어 있는 nlsw88 데이터를 예제로 사용할 것이다.
sysuse nlsw88

nlsw88 데이터를 간략히 살펴보면 변수로 idcode, age, race, … tenure 등이 있다. 여기서 idcode는 개별 id에 해당하며, race는 인종으로 본 예제에서 집단 변수로 사용할 예정이다. 그리고 종속변수로 활용할 변수는 wage이며, 독립변수로 age와 grade를 투입해보고자 한다.
먼저 무조건모형을 돌리기 위해 첫번째 syntax를 입력해보도록 하자.
mixed wage || race:, var
해당 예제에서 연구자는 종속변수 wage가 race라는 집단에 따라 차이가 있는지 분석하고자 한다. 참고로 nlsw88 데이터에서 race 변수는 백인, 흑인, 기타 3가지로 코딩이 되어 있고, 이 race라는 변수가 2수준의 ID에 해당한다. 분석결과는 아래 사진과 같다.
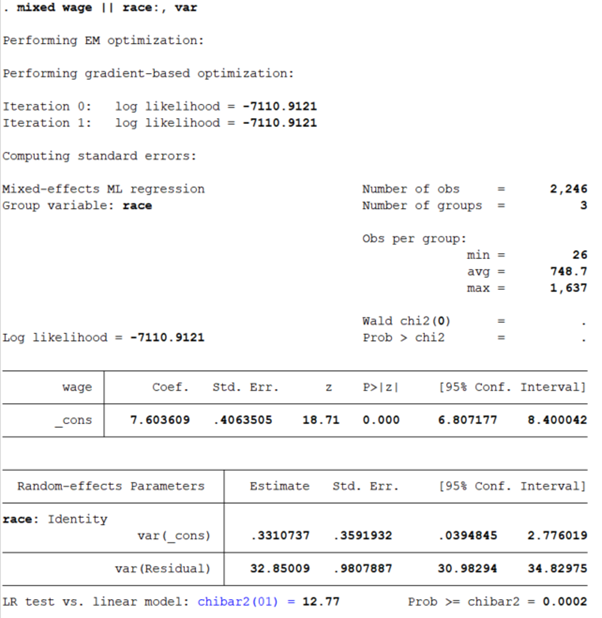
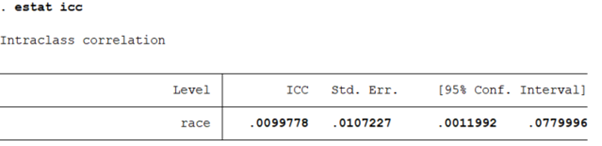
사진에서와 같이 race를 group variable로 하여 분석이 진행되었으며, 종속변수 wage의 분산 중 집단 간 차이가 차지하는 비율이 통계적으로 유의한지 확인한 후 조건모형으로 넘어가야 한다. 참고로 다층모형 분석 결과에서 icc 값을 제시하기도 하는데, 이를 확인하기 위해서는 아래와 같은 syntax를 입력해야 한다.
estat icc : icc 값을 확인하기 위한 명령어
'통계공부 > Stata' 카테고리의 다른 글
| 논문 따라 패널 데이터 분석하기: 서미정(2011)(1) (0) | 2021.03.15 |
|---|---|
| [Stata] 다층모형 분석 관련 명령어(2): mixed (3) | 2021.02.17 |
| [Stata] 로지스틱 회귀분석 관련 명령어: logit, mlogit (3) | 2020.10.08 |
| [Stata] 회귀분석 관련 명령어(2): predict, rvfplot, estat, kdensity, swilk (0) | 2020.10.02 |
| [Stata] 회귀분석 관련 명령어(1): reg, hireg (1) | 2020.04.22 |