
이전 포스팅에 이어 한국아동패널의 1차년도 자료를 활용한 서미정(2011)의 논문을 따라 통계 분석을 진행해보았으며, 참고문헌은 아래와 같다.
서미정(2011). 부모의 심리사회적 특성이 후속 출산계획에 미치는 영향: 유자녀 가구를 중심으로. 육아정책연구, 5(1), 127-148.
이전 포스팅에 이어 조사대상자의 인구사회학적 특성을 분석하고자 한다.
2. 이상자녀수
이상자녀수에 대한 빈도분포표를 얻기 위해 사용할 변수는 "모" 이상 자녀 수(EMt08brp004)이다. 먼저 명령어 tab을 이용해 해당 변수의 응답이 어떻게 코딩되어 있는지 살펴보자.

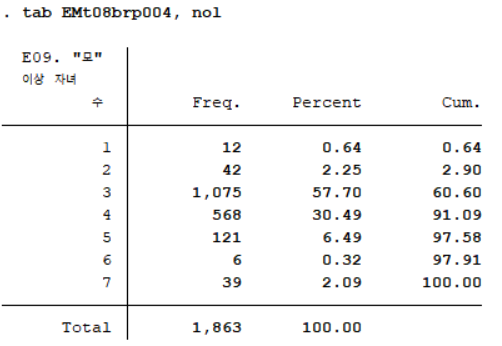
위의 두 사진에서 알 수 있듯이 해당 변수는 무자녀 1, 1명 2, 2명 3, 3명 4, 4명 5, 5명 이상 6, 잘 모르겠음 7로 코딩되어 있다. 앞선 자녀수를 분석했을 때와 유사하게 '잘 모르겠음'이라는 응답은 결측치로 처리하는 것이 좋기 때문에 아래와 같은 명령어를 입력한다.
recode EMt08brp004 (1=1) (2=2) (3=3) (4=4) (5=5) (6=6) (7=.), gen(in_child)
[Stata] 기본 명령어(7): replace, recode
이번 포스팅에서는 Stata의 기본 명령어 중 replace, recode에 대해 알아보고자 한다. 여기서 말하는 기본 명령어란, Stata 프로그램의 세팅과 관련된 명령어와 데이터(혹은 변수) 조작과 관련한 기초
graduationplease.tistory.com
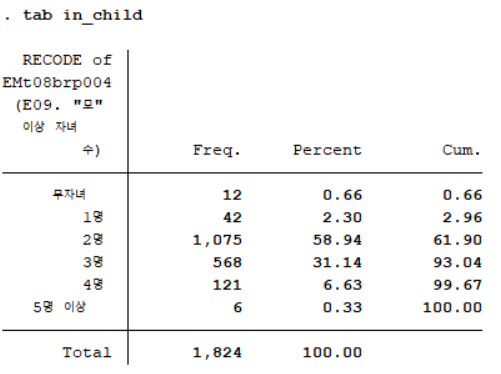
"모" 이상 자녀 수(EMt08brp004)를 리코딩하여 만든 'in_child'의 빈도분포표는 아래 사진과 같다.

그런데 여기서 유의할 점이 기존 변수를 리코딩하여 새로 만든 'in_child'라는 변수에는 labeling이 되어있지 않다는 점이다. 그렇기 때문에 in_child라는 변수의 개별 변숫값들이 무엇을 의미하는지 알 수 없다는 것이다. 특히 지금과 같이 무자녀를 1, 1명을 2, 2명을 3, ..., 5명 이상을 6이라고 코딩한 경우 나중에 데이터를 봤을 때 변숫값 1을 보고 이상 자녀수를 무자녀가 아닌 1명이라고 착각할 수 있다. 따라서 이러한 실수를 방지하기 위해 새로 만든 변수에 label을 달 것이다.
변수 labeling과 관련하여 STATA 프로그램 상단을 보면 아래 사진과 같이 여러 개의 아이콘이 있는데, 이 중 ⑩번이 변수관리창이다. 해당 아이콘을 클릭하면 변수의 이름과 설명(label) 등을 보다 편리하게 편집할 수 있다.

⑩번 변수관리창을 클릭하면 아래 사진과 같은 화면이 뜬다. 이 중 나는 변수 'in_child'의 label을 정해줄 것이므로 빨간 네모로 표시된 Manage를 클릭한다.

위의 사진에서 Manage를 클릭하면 아래 제일 왼쪽과 같은 화면이 뜨는데, 거기서 Create Label 아이콘을 클릭하면 중간 사진과 같은 화면이 뜬다. 중간 사진에서 Value는 변수값, Label은 변숫값에 해당하는 label을 의미한다. 무자녀 1, 1명 2, 2명 3, 3명 4, 4명 5, 5명 이상 6으로 코딩을 해주어야 하므로 맨 오른쪽 사진과 같이 입력을 해준 뒤 빨간 네모로 표시된 OK를 누르면 된다.

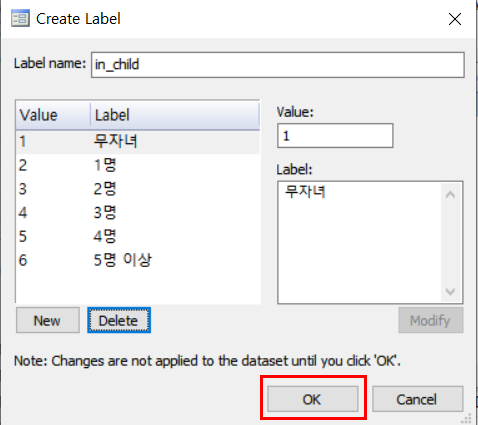
이러한 클릭 과정이 귀찮다면 아래와 같은 명령어를 입력해도 된다.
label define in_child 1 "무자녀" 2 "1명" 3 "2명" 4 "3명" 5 "4명" 6 "5명 이상"
마지막으로 방금 생성한 in_child라는 labeling을 변수 in_child에 적용하기 위해 아래 사진과 같이 Variable Manger에서 Value Label을 in_child로 지정을 하거나 아래와 같은 명령어를 입력한다.
label values in_child "in_child"

'통계공부 > Stata' 카테고리의 다른 글
| 논문 따라 패널 데이터 분석하기: 서미정(2011)(5) (0) | 2021.03.19 |
|---|---|
| 논문 따라 패널 데이터 분석하기: 서미정(2011)(4) (0) | 2021.03.18 |
| 논문 따라 패널 데이터 분석하기: 서미정(2011)(2) (0) | 2021.03.16 |
| 논문 따라 패널 데이터 분석하기: 서미정(2011)(1) (0) | 2021.03.15 |
| [Stata] 다층모형 분석 관련 명령어(2): mixed (3) | 2021.02.17 |