
지난 포스팅에서 Mplus 프로그램을 이용하여 잠재계층분석(Latent Class Analysis; LCA)과 잠재프로파일분석(Latent Profile Analysis; LPA)의 기본 syntax를 설명하였다. 그런데 댓글로 잠재계층분석 혹은 잠재프로파일분석에 관한 추가 질문이 많이 달려, 보충 설명을 하고자 이번 포스팅을 준비하였다. 이에 이번 포스팅에서는 LCA 혹은 LPA 분석에서 도출된 계층에 대한 기술통계분석(평균, 표준편차) 결과를 확인하는 방법과 잠재계층을 데이터로 저장하는 법에 대해 다룰 것이다.
*설명을 위해 노언경, 정송, 홍세희 (2014)의 데이터 분석을 따라해보고자 한다. 해당 연구는 한국청소년정책연구원의 2011년 아동청소년 정신건강 증진 지원방안 연구 자료를 사용하였다. 원자료는 한국아동청소년 데이터 아카이브 홈페이지에서 다운로드할 수 있다.
잠재분석에서는 연구자가 특정 변수의 분포에 있어 이질적인 분포가 있다고 가정을 한다. 노언경, 정송, 홍세희 (2014)는 종속변수를 비행으로 설정하였으며, 데이터에 해당하는 변수명은 “Q6_1 ~ Q6_10”이다.
Q6. 최근 1년 동안, 다음과 같은 경험을 얼마나 해보았습니까?
1) 담배를 피운 적이 있다.
2) 술을 마신 적이 있다.
3) 남의 돈이나 물건을 슬쩍 훔친 적이 있다.
4) 다른 사람을 심하게 때린 적이 있다.
5) 남의 돈이나 물건을 뺏은 적이 있다.
6) 학교를 이유 없이 맘대로 결석한 적이 있다.
7) 가출을 한 적이 있다,
8) 인터넷 성인사이트를 본 적이 있다.
9) 돈내기 도박을 해본 적이 있다(인터넷 포함).
10) 공공장소에 있는 기물이나 다른 사람의 물건을파손시킨 적이 있다
*각 질문의 경험 빈도는 '1=전혀 없음', '2=1~2번', '3=3~4번', '4=5번 이상', '9=모름/무응답'으로 응답 가능하다.
그렇다면 이제 Mplus 코드를 입력해보도록 하자.
TITLE: this is an example of a LPA
DATA: FILE IS LPA.dat;
VARIABLE: Names are ID Q6_1 Q6_2 Q6_3 Q6_4 Q6_5 Q6_6 Q6_7 Q6_8 Q6_9 Q6_10;
USEVARIABLES = Q6_1 Q6_2 Q6_3 Q6_4 Q6_5 Q6_6 Q6_7 Q6_8 Q6_9 Q6_10;
CLASSES = c(2);
Missing are all (-9999) ;
ANALYSIS: type=mixture;
OUTPUT: tech11 tech14;
논문에서와 마찬가지로 잠재프로파일의 개수를 하나씩 늘려 나가며 Entropy, AIC, BIC, SABIC, LMRLT와 BLRT의 p-value를 점검한다. 여기서 LMRLT와 BLRT의 p-value는 OUTPUT에 명시된 tech11, tech14의 결과에서 확인할 수 있다.
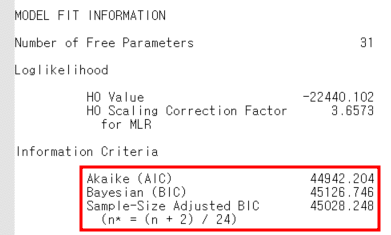


위의 사진은 CLASSES = c(2); 즉, 잠재집단을 2개라고 가정했을 때의 결과를 캡처한 사진이다.
맨 왼쪽 사진의 빨간 네모 안에서는 AIC, BIC, Sample-Size Adjusted BIC 값을 확인할 수 있고, 가운데 사진은 OUTPUT에서 tech11의 분석결과인 LMRLT의 p-value를 확인할 수 있다. 마지막으로 오른쪽 사진은 tech14의 분석결과인 BLRT의 p-value를 확인할 수 있는데, approximate p-value 값을 논문에 보고하면 된다.
위와 같은 방식으로 잠재계층의 개수를 늘려나가면서 Entropy, AIC, BIC, SABIC, LMRLT와 BLRT의 p-value를 비교하여 최종 모형을 선택하는데, 논문에서는 잠재프로파일이 4개인 모형을 최종 모형으로 선택하였다. 그렇다면 이렇게 최종적으로 선택된 4가지 잠재프로파일에 대한 정보는 어떻게 얻을 수 있을 것인가?
여러 가지 방법이 있겠지만 가장 간편한 방법으로는 Mplus에서 바로 해당 유형에 대한 정보를 확인하는 방법이다.
위에서의 syntax 부분에서 CLASSES = c(2);를 CLASSES = c(4);로만 바꾸고 분석을 돌린 다음, MODEL RESULTS 부분에서 4개의 잠재유형에 대한 기초통계값을 확인할 수 있다.


다음으로는 조금 번거로울 수도 있지만 Mplus로 하여금 개별 ID가 어떠한 유형의 잠재프로파일에 속하는지 그 결과값을 저장해달라는 명령어를 입력할 수 있다. 이를 위해서는 추가 'savedata' 부분의 syntax를 입력해주어야 한다.
TITLE: this is an example of a LPA
DATA: FILE IS LPA.dat;
VARIABLE: Names are ID Q6_1 Q6_2 Q6_3 Q6_4 Q6_5 Q6_6 Q6_7 Q6_8 Q6_9 Q6_10;
USEVARIABLES = Q6_1 Q6_2 Q6_3 Q6_4 Q6_5 Q6_6 Q6_7 Q6_8 Q6_9 Q6_10;
CLASSES = c(2);
Missing are all (-9999) ;
ANALYSIS: type=mixture;
OUTPUT: tech11 tech14;
Savedata: file= LPA_result.txt;
save=cprobabilities;
보충 설명을 하자면 file = LPA_result.txt;는 LPA_result라는 txt 파일로 데이터를 저장해달라는 저장 옵션을 지정하는 것이다. 만약 저장 파일의 구체적인 폴더 경로를 정하고 싶다면 이를 기술해줘야 한다. (예시: file=C:\Data\LCA_1213.txt;)
그리고 save=cprobabilities;는 도출된 잠재계층, 여기서는 4개의 개별 잠재계층에 속할 확률과 최종적으로 분류된 잠재계층을 나타내는 값을 저장해달라는 옵션을 의미한다.
위의 syntax를 입력하고 난 뒤 분석이 종료되면, 지정된 경로에 'LPA_result'라는 텍스트 파일이 저장되어 있는 것을 확인할 수 있다. 해당 파일을 열어보면 아래 오른쪽 그림과 같이 생겼는데, 왼쪽에서부터 10번째 열까지는 원래 데이터의 변수였던 Q6_1~Q6_10의 값이 들어가있고(회색 네모), 그 옆의 4개의 열은 4개의 개별 잠재계층에 속할 확률을 뜻한다(파란 네모). 그리고 마지막 빨간 네모 안이 최종적으로 분류되는 잠재계층으로, 예를 들어, 사진에서 첫 번째 줄의 ID는 1번 잠재계층에 속한다는 것을 의미한다.


'통계공부 > Mplus' 카테고리의 다른 글
| [Mplus] 다층모형(Multilevel Modeling) syntax 설명(3) (1) | 2021.02.14 |
|---|---|
| [Mplus] 다층모형(Multilevel Modeling) syntax 설명(2) (0) | 2021.02.13 |
| [Mplus] 다층모형(Multilevel Modeling) syntax 설명(1) (0) | 2021.02.12 |
| [Mplus] 비연속시간 생존분석 syntax 설명 (0) | 2020.09.29 |
| [Mplus] 잠재성장계층분석(LCGA) syntax 설명 (6) | 2020.09.26 |