
Stata 프로그램으로 막대 그래프(bar chart)를 그리는 방법(☞ 포스팅 링크)에 이어 이번 포스팅에서는 파이 그래프(pie chart) 작성 방법에 대해 알아보고자 한다. 지난 포스팅과 마찬가지로 Stata 프로그램에 내재된 데이터셋을 이용할 것이며, 해당 데이터셋에 대한 설명을 위해 Stata의 기본 명령어 중 하나인 codebook에 대한 설명도 함께 하고자 한다.
먼저 stata 데이터셋 중 유권자에 대한 정보를 담은 'voter' 파일을 명령어 sysuse로 불러올 것이다.
sysuse voter
voter 데이터셋을 불러왔다면 먼저 데이터의 구조와 어떠한 변수들이 있는지 확인하기 위해 명령어 describe를 실행한다. describe를 통해 관찰값과 변수의 갯수, 데이터 크기, 개별 변수에 대한 정보를 얻을 수 있다. 그렇다면 이제 개별 변수들의 속성을 보다 자세히 알아보기 위해 명령어 codebook을 사용해보도록 하겠다.

codebook
codebook은 변수의 속성과 코딩이 어떻게 이루어져있는지 파악하는데 사용되는 명령어로, 아래 사진과 같이 개별 변수의 유형, 라벨, 범위, 결측치, 간단한 빈도표 등을 간단하게 확인할 수 있다. candidat, inc와 같은 범주형 변수는 간단한 빈도표를 제시한 반면 frac, pfrac, pop과 같은 연속 변수는 평균과 표준편차, 10%퍼센타일/25%퍼센타일/50%퍼센타일/75%퍼센타일/90%퍼센타일과 같이 간단한 기초통계값도 제시해주고 있다.


얼추 데이터셋에 대한 이해가 되었으니 파이 그래프를 그려보도록 하자. 파이 그래프는 변수의 빈도를 나타날 때 사용되는 그래프로, 파이 그래프 작성을 위한 기초 명령어 형식은 아래와 같다.
graph pie, over(변수명) : 변수의 범주 빈도로 파이 그래프 그리기
graph pie, over(변수명) plabel(...) : 파이 그래프 조각에 라벨을 붙이는 옵션
graph pie, over(변수1) by(변수2) : 변수2의 하위 범주에 따라 변수1의 범주 빈도로 파이 그래프 그리기
먼저 유권자별 빈도분포를 파이 그래프로 나타내기 위한 syntax와 실행결과는 아래와 같다.
graph pie, over(candidat)

파이그래프 그림 결과를 보면 어딘가 심심하다. 이는 파이그래프의 각 조각에 대한 설명이 없기 때문인데, 이를 해결하기 위해 사용할 수 있는 옵션이 plabel이다. 아래 세 가지 예를 보도록 하자.
graph pie, over(candidat) plabel(_all name)
graph pie, over(candidat) plabel(_all sum)
graph pie, over(candidat) plabel(_all percent)
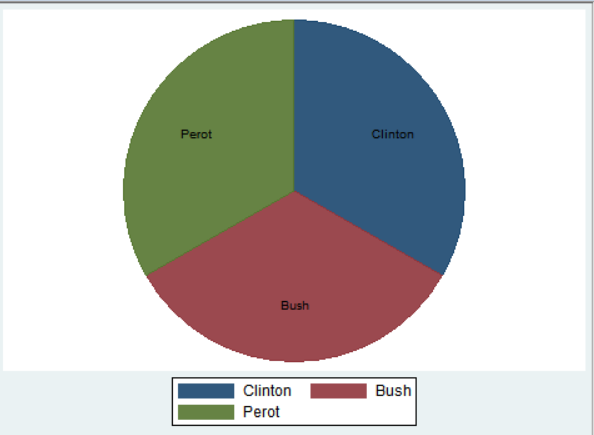

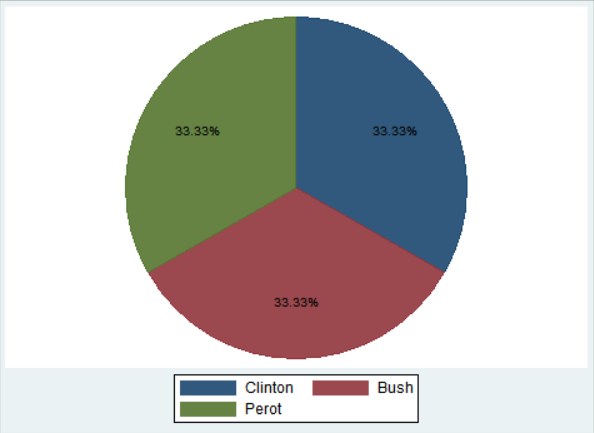
위의 세 가지 파이그래프를 비교하면 알 수 있듯이, _all name은 라벨명을 붙이는 옵션으로 유권자(voter)의 범주명인 Clinton, Bush, Perot이 기입되었다. 가운데 _all sum의 실행결과에서는 해당 범주에 속하는 사례수가 적혀있으며, 맨 오른쪽 _all percent 옵션 결과에서는 범주별 퍼센티지가 나와있다.
이를 총 정리하여 파이조각에 유권자의 이름과 퍼센티지가 나오고, 대신 범례를 지워보도록 하자. 추가로 위의 사진에서 라벨이 잘 안보이기에 글자 크기를 키우고 글자색을 흰색으로 바꿔줄 것이다. 이를 실행하기 위한 명령어 syntax와 그 결과는 아래와 같다.
graph pie, over(candidat) plabel(_all name, size(large) gap(-10) color(white))
plabel(_all percent, color(white)) legend(off)
범례를 지우기 위해 옵션에 legend(off)를 기입하였으며, 파이라벨에 라벨명과 퍼센티지를 기입하기 위해 plabe() 옵션을 사용하였다. plabel 괄호 안을 살펴보면 size(large)는 텍스트 크기를 키우기 위한 옵션이며, 글자색은 color(white)로 수정하였고, gap() 옵션은 파이 그래프 중심으로 텍스트를 가까이 위치시키라는 옵션이다. 이러한 gap 옵션을 사용하지 않으면 라벨명과 퍼센티지가 중복되어 나타나 가독성이 떨어지기 때문이다.


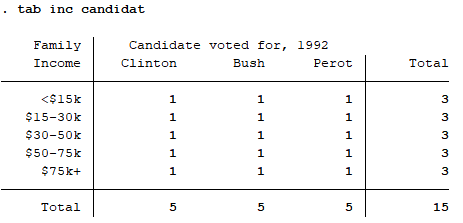
이제 마지막으로 소득구간별로 유권자 빈도에 대한 파이그래프를 그려보도록 하자. 이때 소득구간별(<15k / $15-30k / $30-50k / $50-75k / $75k+)로 파이그래프를 작성하라는 옵션은 by()를 이용한다. 추가로 앞서 사용한 plabel 옵션을 이용하여 퍼센티지를 기입할 것이다.
graph pie , over(candidat) by(inc) plabel(_all percent)

'통계공부 > Stata' 카테고리의 다른 글
| [Stata] 그래프 작성: 막대 그래프(bar chart) (0) | 2021.08.03 |
|---|---|
| [Stata] 그래프 작성의 기초 (0) | 2021.07.28 |
| 논문 따라 패널 데이터 분석하기 - Stata 파일 Mplus 파일로 변환: 신나리, 안재진(2014)(8) (3) | 2021.07.08 |
| 논문 따라 패널 데이터 분석하기 - 역코딩, 척도 평균, t-test: 신나리, 안재진(2014)(7) (0) | 2021.07.05 |
| 논문 따라 패널 데이터 분석하기 - 항목묶기, 크론바하 알파 구하기: 신나리, 안재진(2014)(6) (1) | 2021.07.02 |